
It’s surprisingly difficult to find information related to monitoring a distributed network. I think this is because, in part, network pros take the term for granted. We all intuitively know what they are, and the term is pretty common in conversation. But when you start to think about a precise definition, or even search for one online, things get fuzzy.
What exactly makes a network distributed? Is a distributed network fundamentally different from a decentralized network? And if they’re different, how do we manage it? Even for those of us comfortable with the basics, actually implementing effective monitoring for a distributed network at scale sounds like a difficult technical problem.
Let’s look at exactly what a distributed network is, with an emphasis on TCP/IP networks (sorry blockchain enthusiasts!). Then, we’ll dive into the unique challenges of monitoring distributed networks and how to solve for them.
What is a distributed network?
The definition of a distributed network is a system of interconnected but independent networks, often spread across multiple geographical locations.
Admittedly, our definition of distributed networks is a bit biased towards network engineering. Then again, it’s what we do. You could broaden the definition to refer to interconnected “systems” and I wouldn’t argue. However, this definition allows us to hone in on our specific use cases: geographically distributed networks containing multiple, independent networks within it.
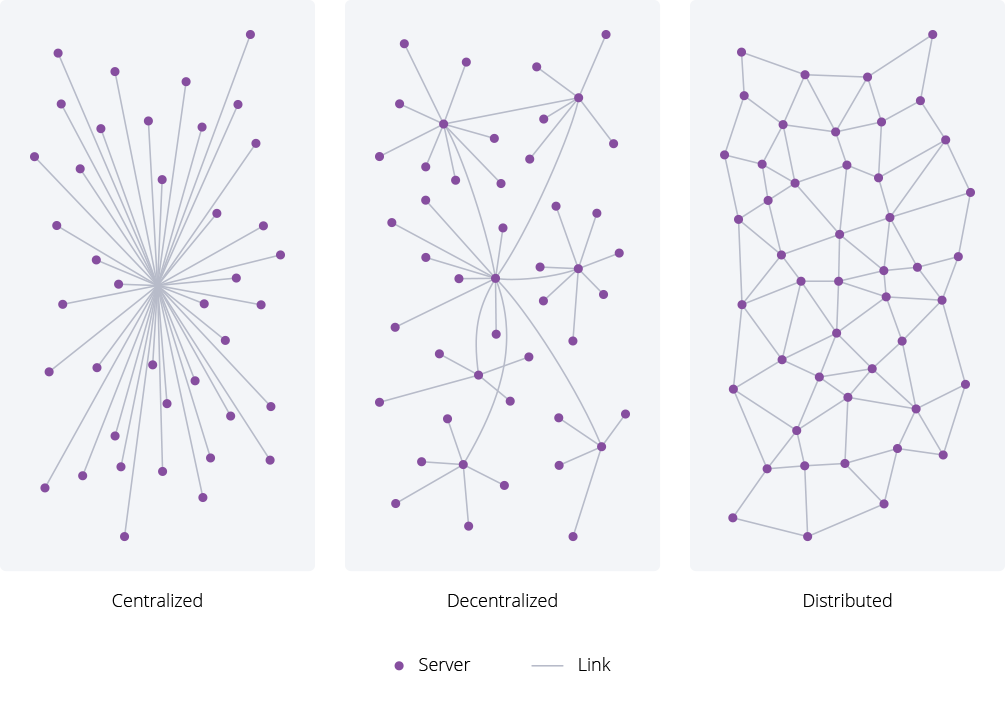
Distributed network vs. centralized networks
To really imagine what a distributed network is, it’s useful to start by picturing centralized networks. With a centralized network, everything depends on a single primary server or set of servers to operate. If the central server goes down, the entire network goes down. A simple on-premise client-server network is a good example.
Distributed network architecture, on the other hand, doesn’t have a single point of failure. In fact, it generally interconnects multiple independent centralized networks. For example, a corporate WAN with branch offices fits our definition. Any individual office—which is effectively a centralized network on its own—may continue to operate if other sites go down, but management and monitoring are often centralized. A CDN (Content Delivery Network) with multiple PoPs (points of presence) also fits our definition. Each PoP is independent, but the entire distributed network comes together to create the CDN.
I’m a bit of a space buff, so I’m going to include a space analogy here. Our solar system (Sol) can be seen as an independent, centralized network, but part of the Milky Way galaxy (our “Pringle-shaped” distributed network of many billions of solar systems). You could even go up further, and see that our happy little galaxy is actually just another independent, centralized network within a massively distributed network we like to call the Virgo Supercluster. Pretty cool, right?
What’s the difference between distributed and decentralized networks?
Since blockchain’s rise in popularity, distributed networks often are confused with decentralized networks. Decentralized networks will NOT have a central control system, while distributed networks generally do. In fact, the presence of a central control system is what helps make many operationally efficient.
Distributed workforces and distributed networks are often associated, but they’re not the same thing. For example, if all employees work from home, at different geographical locations, but use a VPN to connect to the same central server; that’s still a centralized network. Why? Because the entire network depends on a single central server. Be sure to use the right terms if you’re talking about the people in your company logging in to your corporate network, vs the network itself! If you’re really interested in distributed workforce organization, here’s a piece by Jon Ingham.
Common monitoring challenges with distributed networks
The advantages of distributed networking are pretty clear: it improves resilience and scales well. However, distributed networks are also by their nature more complex than centralized networks. There’s more moving parts, and getting the same level of visibility across each individual network in the system can be a real challenge.
In simple terms, the network monitoring challenges of distributed networks are scaled-up versions of centralized network monitoring challenges. Here’s some of the most common challenges facing network administrators tasked with monitoring a distributed network:
- Device discovery. Unless you’re building a network from scratch, or the network is very small, device discovery is usually a challenge. Additionally, network documentation is often lacking, as varied devices don’t always support the same network protocols, and credentials aren’t always known. This issue compounds when you have to perform that discovery across multiple locations that may have different topologies and security policies.
- Network documentation. One of the most common forms of tech debt in network engineering is network documentation. Production networks are never static. Devices fail. Admins make changes to keep the network running. Upgrades and modifications occur. In the day-to-day grind, keeping the documentation up-to-date often falls by the wayside. With distributed networks, this problem scales up.
- Visualization. Effective network visualization can improve everything from capacity planning to network troubleshooting. If you have a clear view of your network’s physical and logical layout, you can make better decisions with less time. With a single site and a centralized network, you often benefit from familiarity with the location and technical staff onsite. With distributed networks, that isn’t usually the case. Every site is a little different, and you can’t know every discrete location like the back of your hand. As a result, you’re more dependent on network maps and monitoring to help you manage the network.
- Scalability. These networks are designed to scale. To effectively monitor, you need tooling that can scale with it. Generally, this means monitoring tools that require a lot of manual configuration, which can become an operational bottleneck in distributed networks.
Specific distributed network monitoring challenges facing MSPs
The monitoring challenges above apply to most distributed networks, including those managed service providers (MSPs) are responsible. However, MSPs often face an additional set of problems corporate IT departments don’t. Fundamentally, this is because MSPs are dealing with multiple customers with different network topologies, security policies, and objectives. In many cases, this means MSPs need a monitoring system that can, in effect, monitor multiple distributed networks. It becomes a case of “distributed networks all the way down”.
Specific challenges common to MSPs working with this architecture include:
- Varying requirements. Different businesses have different performance, security, compliance, and uptime requirements. While SLAs help set a baseline, what an MSP needs to monitor will vary depending on the customer’s business requirements.
- Lack of standardization. In addition to varying requirements, the network devices, topologies, and protocols used across customer networks can also vary widely. For example, one customer may use Windows servers and Cisco network devices, while another uses *nix and Juniper. Similarly, one customer may still have legacy devices that only support SNMP v2c, while another has a strict policy against any plaintext protocols and requires SNMPv3. This makes network monitoring more time-consuming because there is no predictable standard across sites, so everything needs to be a custom solution.
- Isolating sites. For an enterprise IT department, network segmentation is important. However, within a single enterprise, a distributed network is still one large system. With an MSP, we have the aforementioned “distributed networks all the way down” architecture. This creates a tricky monitoring challenge whereby the MSP will need visibility into all sites, but the customer’s IT staff must ONLY have visibility into their infrastructure.
How to effectively monitor distributed networks
Alright, so the problems related to monitoring a distributed network are clear. Now we can move on to discussing how to monitor distributed networks effectively. Here’s some tips for doing just that:
- Automate documentation and discovery. Understanding what devices are deployed on your network, and the logical layout of the entire network, goes a long way. Of course, manually discovering and documenting everything isn’t operationally feasible. Monitoring tools that automate the process of device discovery and network documentation can improve asset management, streamline troubleshooting, and greatly improve overall network visibility. They also help you avoid the “stale documentation” problem that plagues many IT teams.
- Use vendor-agnostic monitoring tools and protocols. You can’t be sure what network devices may pop up. Therefore, it’s important to use vendor-agnostic tooling that can discover a wide range of network devices. Often, when it comes to protocol support, the more, the better. As a starting point, SNMP v1/v2c/v3, flow protocols, SSH, ICMP, IPMI, SMB, HTTP(S), and WMI are a good baseline set of protocols.
- Enable site-level visibility. Remember, each network in a distributed architecture can operate on its own. Often, these “networks” are segmented by geographical location. Setting up your network monitoring to provide visualization, maps, and alerts at the site level can significantly improve visibility and make drilling down to address specific issues simpler. Auvik’s distributed site management provides a great example of how to get this right. You can customize your sites and maps, as well as who has access to them, to meet the specific needs of your distributed network.
- Consider cloud-based monitoring. Because cloud-based monitoring tools are inherently distributed, they’re often a good fit. Cloud-based network monitoring decouples network monitoring from specific sites. This makes it easier to scale and access from anywhere. It also eliminates the complexity of maintaining the infrastructure required to run on-premises tooling. In some cases, as evidenced by Forrester’s recent study of Auvik, cloud-based monitoring can also have significant bottom-line benefits. Some benefits are simply licensing savings, but there’s much more to it than that. My favorite part is the operational benefits. For example, the study indicated that Auvik also simplified network operations to the point junior staff could resolve issues without the need for senior engineers to get involved.
Getting started
Like most things in network engineering, effective monitoring of a distributed network is a mix of the right skills and the right tools. Auvik is a cloud-based solution that many enterprises and MSPs trust for their distributed network monitoring. It’s got you covered with automatic, vendor-agnostic device discovery and documentation, and dynamic mapping, and includes management features like an automated backup of distributed network devices.
Download Auvik’s newest e-book, Seeing is Believing, your up-to-date guide to understanding the value of network visibility, and the elements that you need to step up your game.
Your guide to selling managed network services
Get templates for network assessment reports, presentations, pricing & more—designed just for MSPs.

